{kind=link}
Wie funktioniert eine Suchmaschine? Klar, es gibt einen Crawler, der das Web abgrast und einen Algorithmus, der Ergebnisse nach Relevanz ordnet. Doch für viele SEOs bleibt die genaue Funktionsweise einer Suchmaschine weiterhin ein Mysterium. Gerade in Zeiten, in denen mehrere Core-Updates pro Jahr die Gewichtung beeinflussen, hilft ein grundlegendes Verständnis von Google & Co. bei der Optimierung von Webseiten. Lesen Sie darum den folgenden Detailartikel und erfahren Sie, wie Suchmaschinen eigentlich genau funktionieren.
Inhaltsverzeichnis
- Was ist eine Suchmaschine?
- Wie funktioniert eine Suchmaschine?
- Einfach erklärt: So funktioniert eine Suchmaschine
- Datengewinnung durch Webcrawler-System
- Datenanalyse- und verwaltung
- Suchprozess mit Query-Prozessor
- Personalisierte Ergebnisliste
- Quellen
Was ist eine Suchmaschine?
Bevor man die Funktionsweise einer Suchmaschine verstehen kann, stellt sich erst einmal die Frage, was eine Suchmaschine überhaupt ist? Eine Suchmaschine ist ein Computerprogramm, das basierend auf einer Suchanfrage eines Nutzers eine Datenbank von Dokumenten oder Inhalten durchsucht und entsprechend die relevantesten Ergebnisse in einer Liste anordnet [1]. Die am meisten genutzte Suchmaschine ist Google [2]. Neben Google gibt es noch verschiedene andere Internet-Suchmaschinen, wie z.B. Yahoo, Bing oder DuckDuckGo. Auch die Amazon Produktsuche oder die Pinterest-Suchfunktion zählen zur Gattung der Suchmaschinen und eigenen sich damit für SEO.
All diese Suchmaschinen verfügen über eine Eingabemaske für das Keyword und sortieren die gefunden Resultate anschließend auf einer Ergebnisseite (im Fachjargon: SERP genannt). Auch ist es in den meisten Fällen möglich die Suchanfrage mithilfe von bestimmten Operatoren (z.B. AND & OR) weiter zu verfeinern.
Wie funktioniert eine Suchmaschine?
Anders als häufig angenommen, liefern Suchmaschinen keine Echtzeit-Ergebnisse. Das bedeutet, mit einer Eingabe in die Maske durchsucht ein Nutzer keinesfalls live die verschiedenen Webseiten im Internet. Vielmehr durchforstet er eine Datenbank des Suchmaschinen-Anbieters, die die Inhalte des World Wide Web möglichst genau abbilden soll. Doch bevor Google die Ergebnisse zu einer bestimmten Suchanfrage liefert, werden im Hintergrund zahlreiche verschiedene Prozesse durchlaufen [2]. Diese lassen sich in drei Kernkomponenten unterteilen:
1. Datengewinnung durch Webcrawler-System
Mithilfe eines Crawlers sammelt und speichert die Suchmaschine alle Dokumente des Internets in einer Datenbank. Diese Datenbank wird auf fehlende oder veränderte Dokumente hin überprüft. Durch einen regelmäßigen Abgleich zwischen Datenbank und dem Webangebot wird Aktualität gewährleistet.
2. Datenanalyse durch Information Retrieval-System
Die gesammelten Dokumente aus dem Internet sind für die Suchmaschine nichts anderes als eine Aneinanderreihung von willkürlichen Buchstaben. Daher müssen die Daten mithilfe eines Information Retrieval-Systems in eine für die Suchmaschine lesbare Form umgewandelt werden. Auf Basis von verschiedenen (algorithmischen) Methoden werden den einzelnen Dokumenten sogenannte Gewichte zugeordnet. Diese sind suchwortabhängig und bestimmten die Relevanz einer URL für ein bestimmtes Keyword.
3. Verarbeitung von Suchanfragen durch den Query-Prozessor
Nachdem die Dokumente nun aufgenommen, kategorisiert und gewichtet sind, kann die Suchanfrage des Benutzers beantwortet werden. Dies geschieht mithilfe des Query-Prozessors. Der Query-Proyessor fungiert als Schnittstelle zwischen Suchmaschine und Benutzer. Konkret durchsucht er anhand eines Keywords die Datenbank und bereitet die Ergebnisse in einer gewichteten Liste auf. Diese kennen wir als SERP [3].
Einfach erklärt: So funktioniert eine Suchmaschine
Um es auf den Punkt zu bringen, wie funktioniert eine Suchmaschine jetzt also genau? Der Crawler legt eine Datenbank aller Dokumente des Internets an. Diese Dokumente werden anschließend durch ein Information Retrieval-System vereinfacht, kategorisiert und für bestimmte Suchworte gewichtet. Basierend auf der Suchanfrage des Nutzers, erstellt der Query Prozessor dann eine sortierte Liste der jeweiligen Datenbankergebnissen (SERP) [2].
Die Funktionsweise einer Suchmaschine wird im nachfolgenden Video vom Deutschen Technikmuseum gut beschrieben.
1. Datengewinnung durch Webcrawler-System
Das Webcrawler-System ist die Schnittstelle der Suchmaschine zum World Wide Web und somit elementar für die Funktionsweise einer Suchmaschine. Die Hauptaufgaben des Systems sind das Herunterladen von neuen Dokumenten und das Abgleichen des Datenbestands mit dem Webangebot.
Das Webcrawler-System besteht aus fünf verschiedenen Komponenten:
- Dokumentenindex
- Scheduler
- Crawler
- Storeserver
- Repository
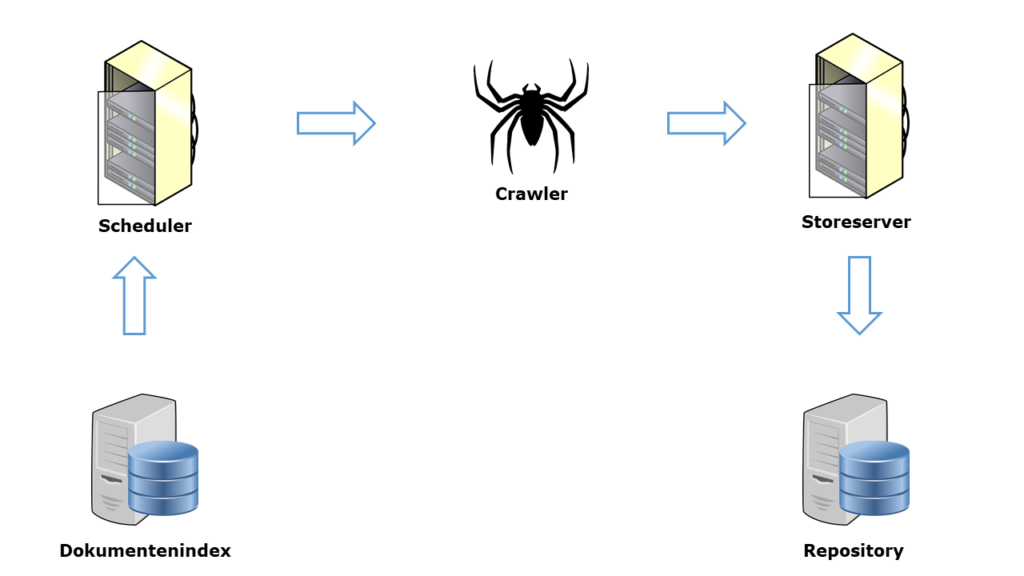
Dokumentenindex
Den Dokumentenindex kann man sich als eine Art Bestandsübersicht vorstellen. Er beinhaltet grundlegende Informationen zu jedem Dokument aus der Datenbank. Hierzu gehören u.a.:
- Zeitstempel des letzten Crawler-Besuchs
- Beobachtete oder berechnete Änderungshäufigkeit
- Dokumentlänge
- Dokumenttyp
- Title tag
- Informationen aus robots.txt oder robots Meta-Tag
- Statusinformationen über den Server
- Hostname und IP-Adresse
Die Dokumente im Index sind nach der sogenannten DocID sortiert. Dies ist ein individueller Schlüssel, mit dem jedes Dokument eindeutig zugeordnet werden kann. Außerdem wird für jedes Dokument auch ein Dokumentenstatus festgelegt. Dieser kann von „noch nicht indexiert“ über „wird gerade gecrawlt“ bis hin zu „indexiert“ variieren.
Eine der wichtigsten Angaben im Dokumentenindex ist die Prüfsumme. Die Prüfsumme ist entscheidend für den Abgleich zwischen dem Dokument im Datenbestand und der Live-URL im World Wide Web. Sie besteht aus verschiedenen Ziffern und Buchstaben und wird mithilfe eines Algorithmus berechnet. Ändert sich auf der Live-URL im Web nur ein Zeichen, verändert sich auch die Prüfsumme. Wenn die Prüfsumme der Live-URL und die des Dokuments im Index nicht übereinstimmen, bedeutet das, dass sich der Inhalt der Website verändert hat und das Dokument im Bestand durch das Webcrawler-System neu indexiert werden muss.
Scheduler
Der Scheduler fungiert quasi als Schichtplan. Er koordiniert und verteilt Aufträge an die verschiedenen Crawler. Die hierfür notwendige Informationen holt er sich aus dem Dokumentenindex. Unterscheidet sich die Prüfsumme des Dokuments im Index von der Prüfsumme der Live-URL, das heißt hat sich der Inhalt auf der Website verändert, plant der Scheduler einen Auftrag zum erneuten Crawlen der URL ein. So sorgt Google dafür, dass es seinen Nutzern stets die aktuellen Ergebnisse präsentiert. Bei einer aktuelleren Dokumentenvariante werden die entsprechenden Parameter anschließend wieder in den Dokumentenindex übertragen [2].
Die Crawlhäufigkeit einer Webseite wird u.a. durch die Linkstruktur, die Änderungshäufigkeit, dem Vorhandensein einer Sitemap sowie der Ladezeit der Website beeinflusst [4].
Crawler
Der Crawler bekommt vom Scheduler die Aufgabe eine bestimmte URL zu besuchen und das entsprechende Dokument abzuspeichern. Dazu ruft er (mittels HTTP-Request die URL auf) und fordert den Server zum Übertragen der Ressource auf. Die Antwort vom Server (HTTP-Response) erhält neben dem Dokument, auch noch einige Header-Informationen. Diese Daten werden zur Weiterverarbeitung an den Storeserver geleitet (siehe nächster Absatz) [2].
Storeserver
Der Storeserver sichert die Daten, die von den Crawlern geliefert werden. Im Wesentlichen hat er drei verschiedene Aufgaben:
- Auswertung der HTTP-Response-Header des Dokuments
- Aktualisierung des Dokumentenindex
- Aufnahmeprüfung für Ressourcen
Beim Aufrufen der URL erhält der Crawler einen Statuscode vom Server (z.B. 404 – Not found oder 301 – Moved permanently). Der Storeserver wertet diesen Statuscode aus und zieht entsprechende Rückschlüsse für den Datenbestand. So löscht er z.B. bei einer Weiterleitung (Statuscode 301) die alte URL aus der Datenbank. So wird der Dokumentenindex fortlaufend durch den Storeserver aktualisiert.
Bevor ein Dokument endgültig in der Repository gespeichert werden kann, muss es im letzten Schritt auf seine Speicherungswürdigkeit und Verarbeitbarkeit hin überprüft werden.
Repository
Im letzten Schritt wird ein Dokument in der Datenbank, der sogenannten Repository gespeichert. Dieser Datenspeicher enthält überwiegend lokale Kopien von HTML-Dokumenten der Webseiten aus dem Netz. Hier wird das Dokument zum Beispiel auf doppelte Inhalte hin überprüft („Duplicate Content“). Mithilfe der „DocId“ kann zwischen den verschiedenen Dokumenten unterschieden werden.
2. Datenanalyse und -verwaltung
Die Suchmaschine will natürlich nur die relevantesten Ergebnisse für ein bestimmtes Suchwort anzeigen. Darum müssen die vom Webcrawler-System gesammelten Dokumente aus der Repository nun so aufbereitet und analysiert werden, dass sie nach Keywords geclustert und gewichtet werden können. Diese Aufgabe übernimmt das Information-Retrieval System innerhalb der Suchmaschine.
Datenaufbereitung durch den Parser
Um Dokumente verstehen und gewichten zu können, müssen diese zuerst so aufbereitet werden, dass sie von der Suchmaschine verstanden werden können. Mithilfe eines mehrstufigen Prozesses erstellt der Parser ein einheitliches Datenformat. Nur so können die Suchanfragen später automatisiert verarbeitet werden.
Konkret werden die folgenden Schritte durchlaufen:
- Datennormalisierung
- Wortidentifikation
- Sprachidentifikation
- Word Stemming
- Mehrwortgruppenidentifikation
- Stoppworterkennung
- Keyword-Gewinnung
- URL-Verarbeitung
Datennormalisierung
Bei der Datennormalisierung geht es darum, unnötige Informationen zu entfernen und relevante Informationen zu speichern. So befreit der Parser das HTML-Dokument aus der Repository von allen HTML-Tags. Nur so kann das Dokument später von der Suchmaschine verstanden und analysiert werden. Gleichzeitig werden relevante Informationen, wie z.B. das title-tag, die h1-h6 Überschriften, Fettungen oder sonstige Hervorhebungen erkannt und im System vermerkt.

Wortidentifikation durch den Tokenizer
Die Suchmaschine ist natürlich kein Mensch. Für sie besteht das normalisierte HTML-Dokument nur aus einer Aneinanderreihung von willkürlichen Zeichen. Um Keywords zu identifizieren und die Semantik eines Dokuments verstehen zu können, muss die Suchmaschine jedoch einzelne Wörter erkennen können.
Hierfür werden sogenannte Wortseparatoren genutzt. Dies sind Zeichen, die der Suchmaschine dabei helfen Wortgrenzen zu identifizieren. Denken Sie z.B. an Leer- und Satzzeichen sowie verschiedene Sonderzeichen, wie # oder +. Der Parser verfügt über eine Liste aller Wortseparatoren.
Neben der Wortseparatoren-Liste besitzt der Parser auch eine Liste mit allen zulässigen Zeichen, die innerhalb eines Wortes vorkommen können. Diese zweite Liste kann man als eine Art Alphabet ansehen.
Nun durchsucht der Parser das normalisierte Dokument Zeichen für Zeichen und überprüft in welcher Liste es vorkommt. Solange der Parser auf ein Zeichen aus dem zulässigen Alphabet stößt, werden die Zeichen aneinandergehängt. Trifft der Parser jedoch auf ein Zeichen aus der Wortseparatoren-Liste werden alle bis dahin gespeicherten Zeichen zu einem Wort zusammengefasst.

Anschließend kann je nach Anbietern ein Lexikon hinzugezogen werden, um sicherzustellen, dass nur lexikalisch sinnige Wörter extrahiert werden. Auch kann es sein, dass Wörter mit nur einem oder zwei Zeichen direkt gelöscht werden.
Identifikation der natürlichen Sprache
Im nächsten Schritt geht es darum, die natürliche Sprache eines Dokuments zu identifizieren. Das bedeutet, Google muss erkennen, dass das es sich bei dem vorliegenden Dokument um z.B. die deutsche oder englische Sprache handelt. Niemand möchte etwas Googlen und sich durch allerlei fremdsprachige Dokumente wurschteln müssen.
Zur Erkennung der natürlichen Sprache wird normalerweise eine Kombination aus verschiedenen statistischen Verfahren und einer Art Wörterbucherkennung genutzt [3]. Die richtige Bestimmung der Sprache ist entscheidend, da die im weiteren Verlauf genutzten Algorithmen zum Teil sehr sprachabhängig sind.
Grundformreduzierung durch Word-Stemming
Das Stemming-Verfahren wird genutzt, um sinngleiche Wörter auf den gemeinsamen Wortstamm zurückzuführen. So können lexikalisch verwandte Wörter, wie z.B. Stuhl und Stühle oder sah und sehen zusammengeführt werden. Schließlich beinhaltet der Stamm die Bedeutung des Wortes. Konjugationen, Endungen oder Vorsilben verändern diese Bedeutung nicht.
Durch die Grundformreduzierung werden die Dokumente erheblich verkleinert, was sich positiv auf die Effizienz der Suchmaschine auswirkt.
Mehrwortgruppenidentifikation
Oftmals besteht ein Wort aus mehreren Begriffen. Dabei kann es vorkommen, dass der Nutzer nicht das komplette Wort eingibt, sondern nur einen Begriff daraus. Ein typisches Beispiel der Mehrwörter ist zum Beispiel das Wort „Marktforschungsinstitut“. Wenn jetzt ein Nutzer nach „Marktforschung“ googelt, ist die Seite des Marktforschungsinstituts natürlich immer noch ein relevantes Ergebnis.
Für die Mehrwortgruppenidentifikation wird ein sogenanntes Mehrwortgruppen-Wörterbuch genutzt.

Stoppwörter
Beim Schreiben eines Textes verwenden wir Menschen eine Vielzahl von Wörtern mit geringer oder gar keiner inhaltlichen Bedeutung. Schauen wir uns doch zum Beispiel den letzten Satz mal etwas genauer an:
„Beim Schreiben eines Textes verwenden wir Menschen eine Vielzahl von Wörtern mit geringer oder gar keiner inhaltlichen Bedeutung“.
Die fett-gedruckten Wörter sind sogenannte Stoppwörter. Diese sind für die Suchmaschine nicht relevant, um die Bedeutung eines Textes zu verstehen. All diese Wörter sind in einer Stoppwort-Liste gespeichert. Die Suchmaschine vergleicht nun das vorliegende Dokument mit dieser Liste und entfernt alle Stoppwörter.
Diese Stoppwortliste gleich einer sogenannten Black List. Mit einer Black List erkennt die Suchmaschine jugendgefährdende Begriffe in einem Dokument und kann dieses Dokument anschließend von der Indexierung ausschließen.
Keyword-Extrahierung
Das Ziel der Suchmaschine ist es natürlich das Thema eines Dokuments möglichst genau zu bestimmen. Dazu müssen die sogenannten Schlüsselwörter (Keywords) identifiziert werden. Alle bisher vorangegangenen Schritte fungieren als eine Art Filter, die der optimalen Keyword-Extrahierung für das jeweilige Dokument dienen.
Nicht jeder Begriff ist ausreichend qualifiziert, um als Keyword zu gelten. Vereinfacht betrachtet müssen Keywords drei Kriterien erfüllen:
- Stichwortvalidität
Die Begriffe müssen später als relevante Stichwörter dienen, anhand derer der Index durchsucht werden kann. Konjunktionen oder Negationen kommen z.B. nicht in Frage, daher werden diese ja auch in vorigen Schritten bereits aussortiert (siehe Stoppwörter).
- Gewichtungsvalidität
Um eine Gewichtung für die Relevanzbestimmung durchführen zu können, müssen Keywords bestimmte Parameter erfüllen. Im Grunde stellt man sich hier die Frage, wie wichtig ein Schlüsselwort für den Inhalt des Textes ist.
- Cluster-Validität
Schlüsselwörter müssen sich für die Bildung von thematischen Verknüpfungen zu anderen Dokumenten, sogenannten Clustern, eignen. [2]
Stellen Sie sich einen Text über einen Friseur in Berlin vor. In diesem Text werden die Begriffe „Friseur“ und „Berlin“ in verschiedenen gestemmten Varianten vorkommen. Doch vielleicht erwähnt der Autor auch, dass sich der Berliner Friseur direkt neben dem Casino befindet. Grundsätzlich ist der Begriff „Casino“ stichwortvalide, allerdings ist er nicht so sehr gewichtungsvalide. Die Begriffe „Friseur“ und „Berlin“ kommen öfter im Text vor und eignen sich daher auch besser, um das Thema des Textes zu beschreiben.
Jetzt könnte man einfach einen Text über einen Friseur in Berlin schreiben, der die Schlüsselwörter so oft wie möglich enthält. Doch das ist nicht im Sinne des Nutzers und wird als „Keyword-Stuffing“ sogar von Google abgestraft.
Dass die reine Häufigkeit, mit der ein Begriff in einem Text vorkommt, nicht ausreichend ist, um seinen Inhalt zu bestimmen, hat bereits der Wissenschaftler Hans Peter Luhn im Jahre 1958 erkannt. Grundsätzlich ist auch er der Meinung, dass die empirische Häufigkeit, mit der ein Begriff vorkommt, Rückschlüsse auf die Thematik des Textes schließen lässt. Allerdings plädiert er für die Nutzung von zwei Schwellwerte, durch die übermäßig häufig oder fast gar nicht auftretende Begriffe herausgefiltert werden können.
Selbstverständlich bilden die oben beschrieben drei Kriterien und die wissenschaftlichen Erkenntnisse von Luhn nur die Basics zur Keyword Extrahierung ab. Wie genau eine Suchmaschine funktioniert und wie die Keyword Extrahierung abläuft, bleibt natürlich streng geheim.
Bekannt ist, dass verschiedene Algorithmen genutzt werden, um die Keywords und die Thematik eines Dokuments zu bestimmen. So arbeiten z.B. die Algorithmus-Updates Google RankBrain, Google Hummingbird und Google BERT daran, dem Nutzer möglichst relevante Ergebnisse zu liefern. Einen interessanten Artikel über das neuste Algorithmusupdate Google BERT finden Sie bei den Kollegen von Searchmetrics.
URL-Verarbeitung
Die letzte wichtige Aufgabe des Parsers ist das Extrahieren von externen und internen Links aus einem Dokument. Die Links werden einer temporären Liste hinzugefügt, dann als absolute URL konvertiert und schließlich im Dokumentenindex abgespeichert. Anschließend wird die URL vom Scheduler an einen Crawler weitergegeben und der ganze Prozess beginnt von neuem. Durch das Herausfiltern von URLs aus bereits gesammelten Dokumenten, kann eine Suchmaschine immer größere Teile des Internets erfassen. So wird auch deutlich, warum die Linkstruktur einer Website besonders wichtig für das effiziente Crawling ist.
Datenstruktur
Selbstverständlich können die Keywords nicht bei jeder Suchanfrage aufs Neue für alle relevanten Dokumente extrahiert werden. Deshalb muss eine durchsuchbare Datenstruktur geschaffen werden. Vereinfacht dargestellt besteht diese aus drei Komponenten:
- Hitlist
- Direkter Index
- Indirekter Index
Hitlist
Die extrahierten Schlüsselwörter müssen mit weiteren Details angereichert werden, um eine Gewichtung der einzelnen Begriffe und damit eine Relevanzbewertung vorzunehmen. Hierbei strebt die Suchmaschine danach, die Eigenschaften eines Keywords möglichst genau zu beschreiben, um eine algorithmische und detaillierte Berechnung des Gewichts zu ermöglichen.
Diese Ansammlung von Informationen nennt man Hitlist. Einige Parameter dieser Hitlist sind bekannt. Zur Illustration werden nachfolgend drei einfache Beispiele genannt:
- Position des Suchbegriffs
Der Grundgedanke hierbei ist, dass ein Schlüsselwort relevanter ist, je weiter oben es im Text auftritt. Neben der globalen Position wird auch unterschieden, ob ein Schlüsselwort z.B. in der H1-Überschrift oder im <body> des Dokuments auftaucht.
- Gesamtvorkommen im Dokument
In der Hitlist wird auch die Häufigkeit, mit der ein Keyword in einem Text vorkommt, vermerkt. Die Idee ist, je häufiger ein Schlüsselwort vorkommt (bis zu einem bestimmten Schwellwert), desto besser beschreibt es das Thema eines Textes.
- Typografische Hervorhebungen
Fettgedruckte oder kursiv formatierte Begriffe sind in der Regel haben für gewöhnlich eine besondere Bedeutung.
Selbstverständlich ist diese Übersicht nicht vollständig. Viele der Informationen in der Hitlist werden natürlich geheim gehalten, da eifrige SEOs so ausschließlich für bessere Rankings in den Suchmaschinen optimieren könnten. Google hingegen will den maximalen Nutzen für seine Benutzer, um seine Position als Nr.1 Suchmaschine weiter zu festigen und so mehr Werbeeinnahmen generieren zu können.
Für jedes Suchwort wird eine eigene Hitlist erstellt. Die Informationen in der Hitlist dienen der Gewichtung einzelner Begriffe und somit der globalen Relevanzbestimmung eines Suchbegriffs für ein Dokument.
Direkter Index
Die Informationen aus der Hitlist werden im direkten Index gespeichert, sodass diese jederzeit zur Verfügung stehen. Mithilfe des direkten Index können nun alle Schlüsselwörter eines bestimmten Dokuments sowie deren Merkmale einfach gefunden und ermittelt werden.
Es ist möglich alle Schlüsselwörter zu einem bestimmten Dokument angezeigt zu bekommen. Das bedeutet die Basis des direkten Index sind immer die Dokumente. Die Suchmaschine möchte jedoch auf Basis eines Schlüsselworts alle relevanten Dokumente anzeigen. Darum wird ein invertierter Index benötigt.
Invertierter Index
Der invertierte Index ist eine Umkehrung des direkten Index. Im invertierten Index erhält jedes Schlüsselwort eine eigene WordID. Dieser WordID sind verschiedene DocIDs zugeordnet. So können sämtliche Dokumente gelistet werden, in denen ein bestimmtes Suchwort vorkommt.
3. Suchprozess mit Query Prozessor
Der Query Prozessor verarbeitet die Anfrage eines Nutzers und liefert eine dazu passende Ergebnisliste an Dokumenten, die nach Relevanz geordnet sind. Die Verarbeitung der Suchanfrage ähnelt der Datennormalisierung des Dokumentenbestands. In beiden Fällen muss ein vom Menschen verfasster Text für die Suchmaschine übersetzt werden, sodass dieser verarbeitet werden kann.
Zuallererst wird die Suchanfrage normalisiert. Das heißt einzelne Wörter werden erkannt, Stoppwörter werden entfernt und das Stemming-Verfahren wird angewendet (siehe Abschnitt Datenanalyse).
Anschließend wird eine Query (Suchanfrage) erstellt. Diese enthält nur noch die für die Suchmaschine nötigsten Elemente. Die Suchanfrage „Wie lang ist der Nil?“ könnte zum Beispiel in der Query „lang Nil“ resultieren. Dabei stellt der Begriff „lang“ auch die gestemmte Variante des Nomens Länge dar. Anschließend könnte der invertierte Index nach den Schlüsselworten „Länge“ und „Nil“ durchsucht werden.
Normalerweise wird dann ein Thesaurus eingesetzt. Dies ist ein Wortnetz von Begriffen, die miteinander verbunden sind und somit in inhaltlicher Beziehung zueinanderstehen. So erkennt die Suchmaschine zum Beispiel Synonyme oder Oberbegriffe.
Danach findet das eigentliche Matching statt. Hierbei werden die Begriffe der Suchanfrage in WordIDs übersetzt. Diese WordIDs werden anschließend im invertierten Index gesucht. So erhält die Suchmaschine eine Auswahl an Dokumenten, die den genutzten Begriff enthalten. Mithilfe der Hitlist werden weitere algorithmische Berechnungen durchgeführt, die für die Gewichtung der Dokumente entscheidend sind. So werden zum Beispiel externe Verlinkungen mittels PageRank betrachtet. All diese Maßnahmen führen zu einer gewichteten Auswahl an Dokumenten, die für einen bestimmten Suchbegriff interessant sind.
Basierend auf der Gewichtung der einzelnen Dokumente erstellt die Suchmaschine anschließend eine Trefferliste. Ergebnisse auf der ersten Seite sind hierbei am relevantesten, während Ergebnisse auf den hinteren Seiten weniger stark für die einzelnen Suchbegriffe gewichtet werden.
Personalisierte Ergebnisliste
Richtet man sich starr nach oben beschriebenen Verfahren, würde jeder Nutzer dieselben Suchergebnisse erhalten. Um die Relevanz für den Nutzer weiter zu erhöhen, erstellen Google & Co. jedoch personalisierte Ergebnislisten. Hierbei verändern sich die Suchergebnisse basierend auf z.B. dem Standort des Nutzers, den historischen Suchanfragen oder des Nutzerverhaltens im Web.
Quellen
[1] https://www.merriam-webster.com/dictionary/search%20engine
[2] Erlhofer, S. (2019). Suchmaschinen-Optimierung: Das umfassende Handbuch.
[3] https://www.seo-kueche.de/lexikon/query/
[4] https://www.seo-ambulance.de/nachrichten/suchmaschinenoptimierung/indexierung-und-crawl-haufigkeit-durch-suchmaschinen-verbessern/
1 Kommentar
[…] jede Suchmaschine möchte Pinterest genau die Inhalte anzeigen, die die Suchanfrage des Nutzers bestmöglich bedienen. […]